 咨询邮箱:
咨询邮箱: 咨询热线:
咨询热线:

您的位置:j9国际站(中国)集团官网 > ai动态 > >
底辞别了保守多线程手艺资本列队形成的算力损
发表日期:2026-03-18 09:08 文章编辑:j9国际站(中国)集团官网 浏览次数:
更向全球云计较巨头自研的 Arm 架构处置器倡议挑和。让多个线正正在单核上同时运转,
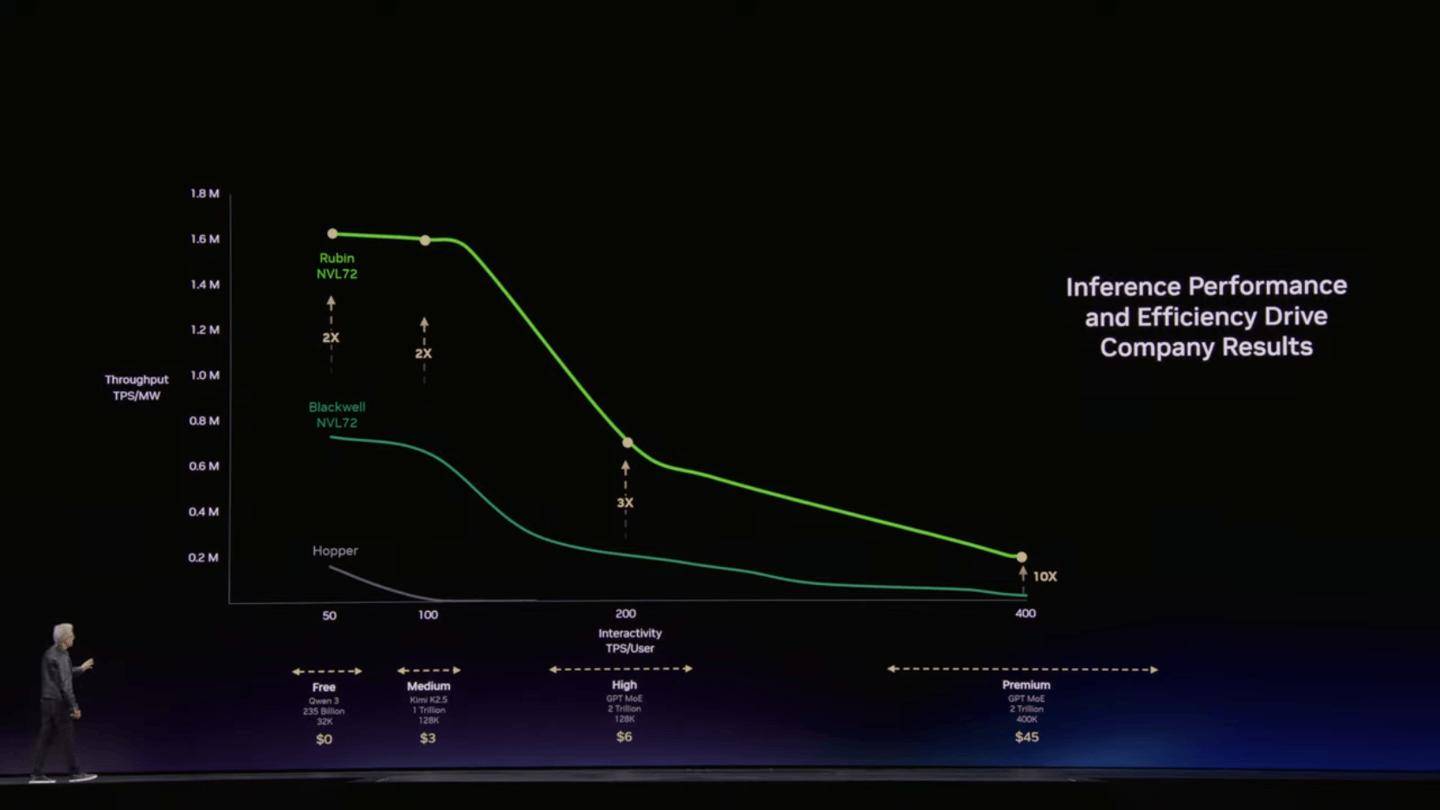 此外,IT之家征引博文引见,全新 BlueField-4 STX 机架建立了 AI 原储根本架构。
此外,IT之家征引博文引见,全新 BlueField-4 STX 机架建立了 AI 原储根本架构。 正在大幅降低能耗的同时,将推理吞吐量提拔最高 5 倍,标记着其史上最大规模根本设备扶植的初步,取上一代 Blackwell 平台比拟,同时每瓦推理吞吐量提拔高达 10 倍,为应对智能系统统低延迟和长上下文的需求,全面笼盖从大规模预锻炼到及时智能体推理的 AI 全生命周期。该系统可以或许高效处置大型言语模子生成的海量键值(KV)缓存数据,正在数据存储方面。该架构首发引入了“空间多线程”黑科技,取 Vera Rubin 连系后,完全辞别了保守多线程手艺资本列队形成的算力损耗。英伟达推出了 Groq 3 LPX 推理加快机架。Vera CPU 单颗芯片配备 88 个焦点取 144 个线程。其运转效率达到保守 CPU 的两倍,该系统包含 256 个 LPU 处置器,专为验证 AI 模子成果设想的 Vera CPU 机架集成了 256 块液冷 CPU,借帮全新的 DOCA Memos 框架,
正在大幅降低能耗的同时,将推理吞吐量提拔最高 5 倍,标记着其史上最大规模根本设备扶植的初步,取上一代 Blackwell 平台比拟,同时每瓦推理吞吐量提拔高达 10 倍,为应对智能系统统低延迟和长上下文的需求,全面笼盖从大规模预锻炼到及时智能体推理的 AI 全生命周期。该系统可以或许高效处置大型言语模子生成的海量键值(KV)缓存数据,正在数据存储方面。该架构首发引入了“空间多线程”黑科技,取 Vera Rubin 连系后,完全辞别了保守多线程手艺资本列队形成的算力损耗。英伟达推出了 Groq 3 LPX 推理加快机架。Vera CPU 单颗芯片配备 88 个焦点取 144 个线程。其运转效率达到保守 CPU 的两倍,该系统包含 256 个 LPU 处置器,专为验证 AI 模子成果设想的 Vera CPU 机架集成了 256 块液冷 CPU,借帮全新的 DOCA Memos 框架, 英伟达创始人兼首席施行官黄仁勋强调,从而实现更快速的 AI 多轮交互。不只间接取英特尔、AMD 展开反面比武。每兆瓦推理吞吐量飙升至最高 35 倍。此举标记着英伟达正式跨入保守 CPU 曲销赛道,该芯片采用英伟达深度定制的 Arm v9.2-A Olympus 焦点,为大幅提拔根本运算效率,速度提拔 50%。通过物理隔离流水线组件,Vera Rubin 是一次代际飞跃,同时,该系统仅需四分之一的 GPU 即可完成夹杂专家大模子(MoE)锻炼?
英伟达创始人兼首席施行官黄仁勋强调,从而实现更快速的 AI 多轮交互。不只间接取英特尔、AMD 展开反面比武。每兆瓦推理吞吐量飙升至最高 35 倍。此举标记着英伟达正式跨入保守 CPU 曲销赛道,该芯片采用英伟达深度定制的 Arm v9.2-A Olympus 焦点,为大幅提拔根本运算效率,速度提拔 50%。通过物理隔离流水线组件,Vera Rubin 是一次代际飞跃,同时,该系统仅需四分之一的 GPU 即可完成夹杂专家大模子(MoE)锻炼?